Klantdata opschonen voor een TMS-migratie: Waarom puur geautomatiseerde tools falen

De blinde vlek van geautomatiseerde opschoontools in logistiek
Standaard datamigratiesoftware leest kolommen, herkent bestandstypen en kopieert waarden van systeem A naar systeem B. Logistieke data tart deze rechtlijnige logica op dagelijkse basis. Transportoperaties draaien historisch gezien op uitzonderingen, specifieke klantspecifieke afspraken en lokaal opgebouwde werkprocessen. Wanneer een organisatie een nieuw Transport Management Systeem (TMS) implementeert, wordt vaak vertrouwd op geautomatiseerde opschoontools ter voorbereiding. Deze tools lopen echter vast op de operationele context die verscholen ligt in decennia aan ongestructureerde data.
Een datamigratie is fundamenteel een operationele opschoonkans en geen geïsoleerd IT-project. De implementatie van dure, geavanceerde software levert geen meetbare resultaatsverbetering op als de onderliggende data corrupt of incompleet is. Om dit te voorkomen is het essentieel om kritisch naar uw klantdata opschonen of migreren proces te kijken. Het mechanisme van ‘garbage in, garbage out’ manifesteert zich genadeloos in een modern TMS. Waar oudere systemen vaak ruimte boden voor handmatige overrides, vereist een nieuw platform strak geformatteerde data om transportplanningen, ritberekeningen en facturaties automatisch te laten verlopen.
ETL-algoritmes (Extract, Transform, Load) zoeken naar vaste datapatronen. Ze falen sodra ze stuiten op vrije tekstvelden. In de logistiek bevatten deze tekstvelden vitale operationele parameters. Denk aan specifieke laadinstructies per adres, afwijkende venstertijden die in de loop der jaren als tekst zijn ingetypt, of douane-instructies die niet in de formele velden pasten. De publicatie ‘Een nieuw ERP, WMS of TMS? Handvatten voor optimale dataconversie’ valideert deze problematiek door dataconversie te benoemen als een proces dat diepgaande operationele kennis vereist, waarbij simpele lift-and-shift strategieën tekortschieten.
Kiest een operationeel manager voor een lift-and-shift methodiek met geautomatiseerde scripts, dan verhuist de historische wildgroei aan contracten direct mee naar de nieuwe database. Latente fouten, zoals verkeerd gespelde relaties en oude werkafspraken, worden zonder correctie ingeladen. Dit blokkeert de planningsalgoritmes op dag één van de go-live. Ook de publicatie ‘AI Agent voor logistieke backoffice: van boekingsmail tot TMS invoer in 3 seconden’ illustreert hoe lastig het structureren van vrije tekst in de logistieke keten is; boekingsinformatie komt zelden in een voorgekauwd format binnen, wat de historische data in het bronbestand direct vervuilt.
3 kritieke knelpunten in legacy klantdatasets
De migratie naar een nieuw logistiek platform dwingt organisaties om jarenlange ad-hoc processen onder de loep te nemen. Het simpelweg exporteren van een SQL-database naar een nieuw format dekt de lading niet. Operationele datasets bevatten doorgaans specifieke patronen van vervuiling. Door deze vervuiling vooraf te categoriseren, krijgt het management structuur in een ogenschijnlijk onoverzichtelijk project.
Binnen legacy software in de transportsector zien we vijf specifieke velden die historisch gezien ongestructureerd zijn achtergelaten door gebruikers:
Vrije tekstvelden voor laad- en losinstructies: Bevatten vaak ongecategoriseerde veiligheidseisen, benodigd materieel (zoals kooiaap verplicht), of voertuigrestricties.
Opmerkingen rondom vervoerders en charters: De plek waar planners uitzonderingen, kwaliteitsbeoordelingen of tijdelijke restricties noteren.
Lokale douanereferenties: Vaak per land wisselend van format en zonder validatieregels ingevoerd.
Tijdvensters: Niet ingevoerd als strakke timestamps, maar als beschrijvende tekst (“tussen de middag niet bereikbaar” of “voor 10:00 melden”).
Contactpersonen: Afdelingsgenerieke e-mailadressen gemengd met persoonlijke, verouderde gegevens per laad- en losadres.
Zoals het overzicht ‘Legacy systemen data migreren: Stappenplan voor Logistiek’ aangeeft, is het benoemen en aanpakken van per categorie opgedeelde knelpunten de enige methode om migratierisico’s te reduceren. Hieronder vallen drie hoofdcategorieën waar legacy data structureel voor problemen zorgt.
Knelpunt 1: Inconsistente bedrijfsstamdata
Transportbedrijven en logistieke dienstverleners werken vaak jarenlang samen met dezelfde netwerken. Doordat verschillende medewerkers door de jaren heen orders hebben aangemaakt, ontstaat een sterke bevuiling in klant- en leveranciersstamdata. Spellingsvarianten, afkortingen en het willekeurig toevoegen van leestekens maken het onmogelijk voor een systeem om dubbele relaties te herkennen. Een vervoerder kan geregistreerd staan onder “Jansen Transport B.V.”, “Jansen Transport”, “Transportbedrijf Jansen”, of zelfs “J. Transport”.
Een script gericht op deduplicatie zal deze profielen als afzonderlijke entiteiten migreren. Het gevolg in het nieuwe TMS is gefragmenteerde managementinformatie. Inkoopvolumes per vervoerder worden niet juist berekend, waardoor inkoopkracht verloren gaat. Ook leidt dit tot facturatiefouten en dubbel beheerde kredietlimieten in het financiële systeem dat vaak aan het TMS is gekoppeld.
Knelpunt 2: Ongestructureerde tariefafspraken
Standaardprijzen staan in tarieftabellen, maar logistiek maatwerk bevindt zich in de uitzonderingen. Dieseltoeslagen (berekend op basis van wisselende indexen), wachturencompensaties per specifiek land, palletruilsystemen of weekendtarieven worden vaak uit noodzaak in algemene opmerkingenvelden geparkeerd. Binnen oudere TMS-systemen wist de planner of administratief medewerker handmatig de juiste factuur op te maken op basis van deze losse tekst.
Een nieuw transport management systeem rekent prijzen volautomatisch door om de order-to-cash cyclus te versnellen. De pricing engine van een TMS pakt vastomlijnde parameters. Wanneer de afwijkende tariefafspraken tijdens de migratie als platte tekst worden geïmporteerd, slaat het systeem vast bij de berekening van de ritprijs. Facturen vallen in de foutenbak, de cashflow stagneert, en het supportteam wordt overbelast met vragen uit de operatie.
Knelpunt 3: Verouderde compliance-informatie
Compliance-data vereist actieve validatie, een functionaliteit die in statische logistieke archieven vaak ontbreekt. Tijdens een migratie komen duizenden records mee waarvan de bedrijfsstatus al jaren niet is gecontroleerd. Het inladen van verlopen BTW-nummers of ongeldige EORI-registraties verstoort de geautomatiseerde douaneprocessen en btw-verleggingsregelingen direct na de overstap.
Douanesystemen en moderne TMS-pakketten controleren de formaten en geldigheid aan de poort. Ontbreekt de structuur in het nieuwe systeem omdat het oude systeem vervuilde data bevatte, dan staan zendingen stil. Het herstellen van deze compliance-fouten op het moment dat de vrachtwagen al gepland is, zorgt voor hoge operationele vertragingen.
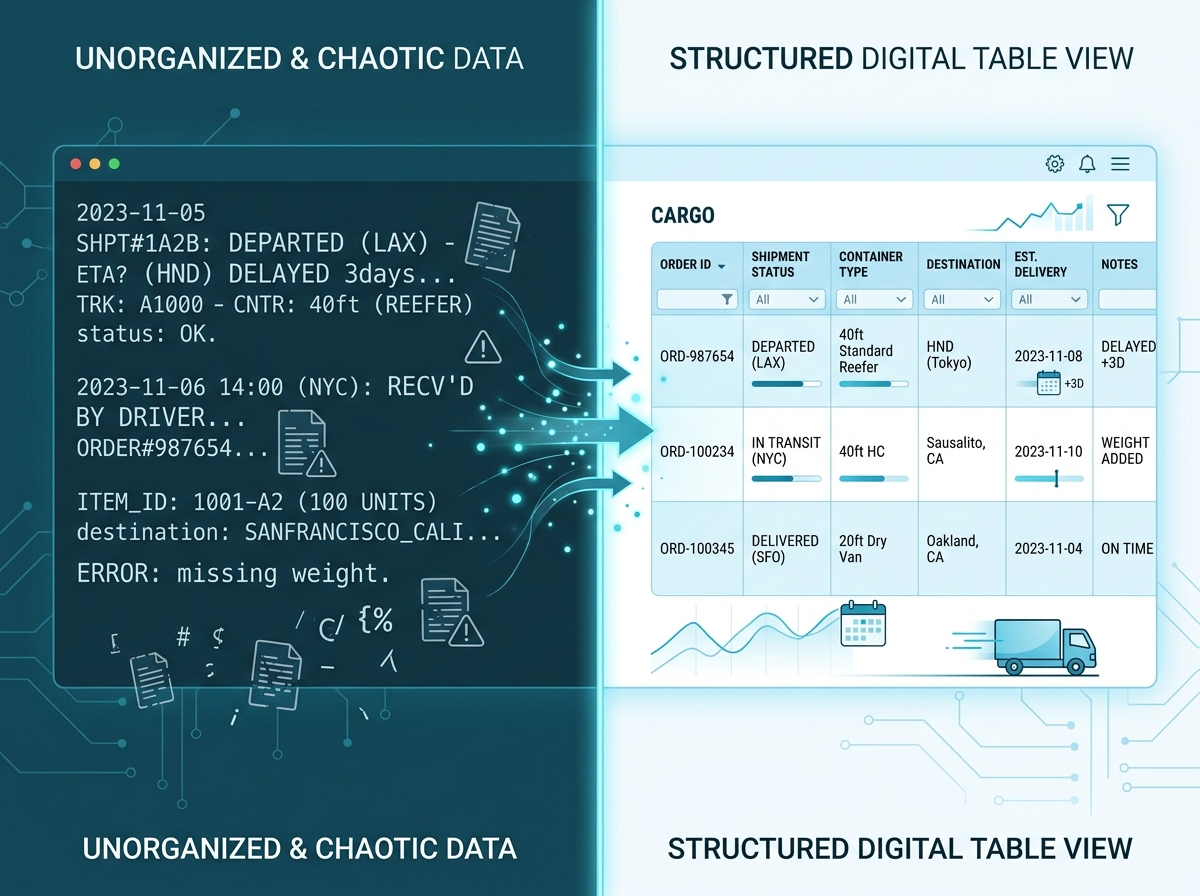
De hybride workflow: RPA combineren met logistiek backoffice-talent
De complexiteit van logistieke data vereist een aanpak die de schaalbaarheid van technologie verenigt met de scherpte van de mens. De hybride werkwijze heeft zich ontwikkeld tot de standaard voor BPO-projecten (Business Process Outsourcing) met een hoge mate van Data Accuracy. Hierbij wordt pure automatisering ingezet voor volumes, terwijl menselijk inzicht gereserveerd wordt voor context en structurering.
Robotic Process Automation (RPA) is sterk in vastomlijnde, binaire taken. Binnen het opschoonproces worden software robots ingezet om absolute formaten recht te trekken. RPA filtert exacte dubbele records (“Jansen B.V.” en “Jansen B.V.”) af op basis van adresgegevens. RPA normaliseert postcodes, zet kleine letters om in hoofdletters in landcodes, en formatteert datumnotaties naar één universele ISO-standaard. Het volume van de data wordt hiermee sterk gereduceerd en de leesbaarheid voor het nieuwe systeem gegarandeerd.
De kracht van de hybride workflow start op het punt waar RPA en standaard scripts stoppen. De data die de robot niet met 100% zekerheid kan koppelen of herformatteren, valt in een zogenaamde exception-lijst. Dit zijn de vrije tekstvelden met laadinstructies, de inconsistent gespelde bedrijfsnamen zonder uniek adres, en de weggemoffelde tariefafspraken. Om deze exception-lijst te verwerken, hanteren domeinspecialisten een strikte beslisboom:
Kan een harde regel de data valideren zonder contextverlies?
Ja: De data wordt behandeld door het RPA-script.
Nee: Ga naar stap 2.
Bevat de record na script-validatie ongestructureerde velden, lege velden of conflicterende formaten?
Ja: De record wordt geïsoleerd en toegevoegd aan de handmatige exception-lijst.
Vereist de opmerking in het vrije tekstveld interpretatie (bijv. “Tarief +5% op vrijdag, mits chauffeur wacht”)?
Ja: Handmatige review door een logistiek backoffice-specialist, die de tekstuele regel omzet naar gestructureerde, binaire parameters passend bij het format van het nieuwe TMS.
Terugkoppeling na correctie:
De handmatig gestructureerde data wordt teruggeplaatst in de schone, gevalideerde migratie-pool.
Deze systematische aanpak, een wisselwerking tussen mens en machine, borgt de continuïteit na go-live. Systemen slaan niet vast op onbekende karakters, en de backoffice verliest in de eerste weken geen tijd aan retroactief velden corrigeren.
Databeveiliging borgen tijdens de transitiefase
Het opschonen van stamdata betekent in de praktijk dat klantinformatie, tariefstructuren, historische ritten en strategische contracten extern verwerkt moeten worden. Dit roept direct vragen op over databeveiliging en continuïteit, specifiek bij COO’s en compliance officers. Het is een volstrekt logische reactie om terughoudend te zijn bij de export of een externe partij klantdata opschonen of migreren te laten uitvoeren voor het fundament onder uw bedrijfsvoering.
Een correcte uitvoering van een datamigratie-opschoning vindt altijd plaats in afgeschermde datasilo’s, volledig buiten de actieve ERP-, TMS- of WMS-systemen om. Pas nadat de data ge-exporteerd, genormaliseerd, gemapt en verrijkt is, vindt er een import plaats naar het test- of productie-omgeving van het nieuwe pakket. Dit voorkomt enige operationele verstoring of overbelasting van de actieve systemen. De vrachtwagens blijven rijden en de planning kan ongehinderd doorwerken gedurende het gehele voorbereidingstraject.
De keuze voor de exacte locatie waar deze data wordt ingezien en gecorrigeerd is direct gekoppeld aan de Europese wet- en regelgeving. Door te opereren binnen het kader van Nearshoring, waarbij fysieke operations centers zich binnen de Europese Unie (zoals Roemenië) bevinden, waarborgt men volledige EU-compliance. De verwerking van bedrijfsgevoelige en persoonsgebonden logistieke data valt hiermee direct onder de strikte kaders van de AVG/GDPR. Er wordt geen data buiten het Europese continent gehost of bewerkt. Dit elimineert de privacyrisico’s die vaak gepaard gaan met procesuitbesteding waarbij de jurisdictie onzeker is, en levert tegelijkertijd de noodzakelijke schaalbaarheid om grote volumes legacy data efficiënt op te schonen voor de migratiedatum.
De Volgende Stap In Uw Migratie
Het uitsluitend inzetten van geautomatiseerde tools tijdens een datamigratie leidt in de complexe logistieke sector gegarandeerd tot vastlopende processen. De effectiviteit en efficiëntie van een nieuw Transport Management Systeem is een harde, directe afspiegeling van de kwaliteit van de geïmporteerde data. Door de opschoonfase te benaderen via een hybride workflow van RPA gecombineerd met domeinspecifieke menselijke expertise in een beveiligde EU-omgeving, transformeert de historische data-vervuiling naar een solide digitaal fundament voor de toekomst.
Wilt u de risico’s bij de implementatie van uw nieuwe TMS of ERP minimaliseren en zorgen voor een foutloze go-live? Overweeg dan professioneel uw klantdata opschonen of migreren en vraag een proces-scan aan bij DataMondial. Onze specialisten brengen uw ongestructureerde logistieke legacy data in kaart en ontwikkelen een concreet, veilig en efficiënt opschoonplan dat uw operatie direct meetbare Data Accuracy oplevert. Neem contact op voor een kennismaking, dan bespreken we uw migratietraject in detail.

